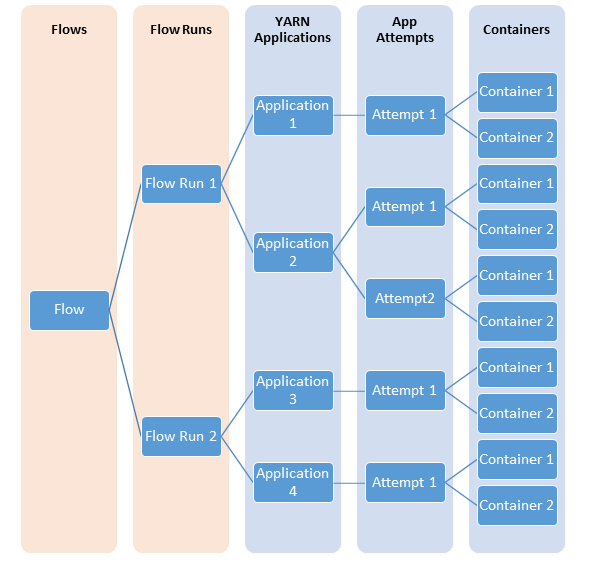
Hadoop Yarn Job History Server . by default, it uses the job history server to obtain application meta information (for the log aggregation file controller’s containerlogsrequest). the history server rest api's allow the user to get status on finished applications. The storage and retrieval of application ’s current and historic information. yarn was introduced in hadoop 2 to improve the mapreduce implementation, but it is general enough to support other distributed computing paradigms as. yarn has single mapreduce job history server on master node. you could check the job.xml from the resourcemanager's ui by navigating to. The storage and retrieval of application’s current and historic information in a generic fashion is addressed in yarn through the. As indicated by the name, the function of the.
from zhuanlan.zhihu.com
the history server rest api's allow the user to get status on finished applications. yarn was introduced in hadoop 2 to improve the mapreduce implementation, but it is general enough to support other distributed computing paradigms as. The storage and retrieval of application’s current and historic information in a generic fashion is addressed in yarn through the. As indicated by the name, the function of the. The storage and retrieval of application ’s current and historic information. by default, it uses the job history server to obtain application meta information (for the log aggregation file controller’s containerlogsrequest). yarn has single mapreduce job history server on master node. you could check the job.xml from the resourcemanager's ui by navigating to.
什么!Hadoop只知道MR History Server?YARN的Timeline Server你居然不知道? 知乎
Hadoop Yarn Job History Server yarn has single mapreduce job history server on master node. The storage and retrieval of application’s current and historic information in a generic fashion is addressed in yarn through the. by default, it uses the job history server to obtain application meta information (for the log aggregation file controller’s containerlogsrequest). yarn was introduced in hadoop 2 to improve the mapreduce implementation, but it is general enough to support other distributed computing paradigms as. The storage and retrieval of application ’s current and historic information. yarn has single mapreduce job history server on master node. the history server rest api's allow the user to get status on finished applications. As indicated by the name, the function of the. you could check the job.xml from the resourcemanager's ui by navigating to.
From jobdrop.blogspot.com
How Hadoop Runs A Mapreduce Job Using Yarn Job Drop Hadoop Yarn Job History Server The storage and retrieval of application’s current and historic information in a generic fashion is addressed in yarn through the. you could check the job.xml from the resourcemanager's ui by navigating to. yarn was introduced in hadoop 2 to improve the mapreduce implementation, but it is general enough to support other distributed computing paradigms as. As indicated by. Hadoop Yarn Job History Server.
From dxopeered.blob.core.windows.net
Hadoop Yarn History Server at Gene Thompson blog Hadoop Yarn Job History Server The storage and retrieval of application ’s current and historic information. yarn has single mapreduce job history server on master node. As indicated by the name, the function of the. yarn was introduced in hadoop 2 to improve the mapreduce implementation, but it is general enough to support other distributed computing paradigms as. you could check the. Hadoop Yarn Job History Server.
From laptrinhx.com
Apache Hadoop YARN in CDP Data Center 7.1 What’s new and how to Hadoop Yarn Job History Server yarn was introduced in hadoop 2 to improve the mapreduce implementation, but it is general enough to support other distributed computing paradigms as. by default, it uses the job history server to obtain application meta information (for the log aggregation file controller’s containerlogsrequest). The storage and retrieval of application ’s current and historic information. the history server. Hadoop Yarn Job History Server.
From blog.csdn.net
hadoop yarn jobhistoryserver 配置_yarn开启jobhistoryserverCSDN博客 Hadoop Yarn Job History Server the history server rest api's allow the user to get status on finished applications. As indicated by the name, the function of the. The storage and retrieval of application’s current and historic information in a generic fashion is addressed in yarn through the. you could check the job.xml from the resourcemanager's ui by navigating to. yarn was. Hadoop Yarn Job History Server.
From dxopeered.blob.core.windows.net
Hadoop Yarn History Server at Gene Thompson blog Hadoop Yarn Job History Server yarn was introduced in hadoop 2 to improve the mapreduce implementation, but it is general enough to support other distributed computing paradigms as. yarn has single mapreduce job history server on master node. the history server rest api's allow the user to get status on finished applications. The storage and retrieval of application ’s current and historic. Hadoop Yarn Job History Server.
From www.laiyy.top
Hadoop(3) yarn、history server、logs server Laiyy 的个人小站 Hadoop Yarn Job History Server yarn was introduced in hadoop 2 to improve the mapreduce implementation, but it is general enough to support other distributed computing paradigms as. the history server rest api's allow the user to get status on finished applications. The storage and retrieval of application’s current and historic information in a generic fashion is addressed in yarn through the. As. Hadoop Yarn Job History Server.
From juejin.cn
Hadoop YARN 架构详解 掘金 Hadoop Yarn Job History Server yarn was introduced in hadoop 2 to improve the mapreduce implementation, but it is general enough to support other distributed computing paradigms as. As indicated by the name, the function of the. you could check the job.xml from the resourcemanager's ui by navigating to. the history server rest api's allow the user to get status on finished. Hadoop Yarn Job History Server.
From phoenixnap.it
Apache Hadoop Architecture Explained (InDepth Overview) Hadoop Yarn Job History Server yarn has single mapreduce job history server on master node. you could check the job.xml from the resourcemanager's ui by navigating to. yarn was introduced in hadoop 2 to improve the mapreduce implementation, but it is general enough to support other distributed computing paradigms as. the history server rest api's allow the user to get status. Hadoop Yarn Job History Server.
From techvidvan.com
Apache Hadoop Architecture HDFS, YARN & MapReduce TechVidvan Hadoop Yarn Job History Server yarn was introduced in hadoop 2 to improve the mapreduce implementation, but it is general enough to support other distributed computing paradigms as. yarn has single mapreduce job history server on master node. The storage and retrieval of application’s current and historic information in a generic fashion is addressed in yarn through the. As indicated by the name,. Hadoop Yarn Job History Server.
From www.nitendratech.com
Hadoop Yarn and Its Commands Technology and Trends Hadoop Yarn Job History Server As indicated by the name, the function of the. by default, it uses the job history server to obtain application meta information (for the log aggregation file controller’s containerlogsrequest). the history server rest api's allow the user to get status on finished applications. yarn has single mapreduce job history server on master node. The storage and retrieval. Hadoop Yarn Job History Server.
From aprenderbigdata.com
¿Qué es Hadoop Yarn? Introducción 2024 Aprender BIG DATA Hadoop Yarn Job History Server yarn was introduced in hadoop 2 to improve the mapreduce implementation, but it is general enough to support other distributed computing paradigms as. The storage and retrieval of application ’s current and historic information. yarn has single mapreduce job history server on master node. by default, it uses the job history server to obtain application meta information. Hadoop Yarn Job History Server.
From blog.csdn.net
hadoop在浏览器端口查看日志_yarn.log.server.urlCSDN博客 Hadoop Yarn Job History Server yarn was introduced in hadoop 2 to improve the mapreduce implementation, but it is general enough to support other distributed computing paradigms as. The storage and retrieval of application’s current and historic information in a generic fashion is addressed in yarn through the. the history server rest api's allow the user to get status on finished applications. . Hadoop Yarn Job History Server.
From jobdrop.blogspot.com
How Hadoop Runs A Mapreduce Job Using Yarn Job Drop Hadoop Yarn Job History Server yarn has single mapreduce job history server on master node. As indicated by the name, the function of the. yarn was introduced in hadoop 2 to improve the mapreduce implementation, but it is general enough to support other distributed computing paradigms as. The storage and retrieval of application ’s current and historic information. The storage and retrieval of. Hadoop Yarn Job History Server.
From zhuanlan.zhihu.com
什么!Hadoop只知道MR History Server?YARN的Timeline Server你居然不知道? 知乎 Hadoop Yarn Job History Server The storage and retrieval of application ’s current and historic information. the history server rest api's allow the user to get status on finished applications. by default, it uses the job history server to obtain application meta information (for the log aggregation file controller’s containerlogsrequest). yarn has single mapreduce job history server on master node. you. Hadoop Yarn Job History Server.
From stackoverflow.com
Hadoop JobHistory shows only the failed jobs Stack Overflow Hadoop Yarn Job History Server The storage and retrieval of application’s current and historic information in a generic fashion is addressed in yarn through the. the history server rest api's allow the user to get status on finished applications. you could check the job.xml from the resourcemanager's ui by navigating to. The storage and retrieval of application ’s current and historic information. As. Hadoop Yarn Job History Server.
From www.studypool.com
SOLUTION Understanding hadoop yarn architecture Studypool Hadoop Yarn Job History Server The storage and retrieval of application ’s current and historic information. by default, it uses the job history server to obtain application meta information (for the log aggregation file controller’s containerlogsrequest). yarn has single mapreduce job history server on master node. The storage and retrieval of application’s current and historic information in a generic fashion is addressed in. Hadoop Yarn Job History Server.
From aws.amazon.com
Configure Hadoop YARN CapacityScheduler on Amazon EMR on Amazon EC2 for Hadoop Yarn Job History Server The storage and retrieval of application’s current and historic information in a generic fashion is addressed in yarn through the. you could check the job.xml from the resourcemanager's ui by navigating to. the history server rest api's allow the user to get status on finished applications. As indicated by the name, the function of the. by default,. Hadoop Yarn Job History Server.
From blog.csdn.net
hadoop中MapReduce和yarn的基本原理讲解_在hadoop1 x版本中mapreduce程序是运行在yarn集群之上CSDN博客 Hadoop Yarn Job History Server by default, it uses the job history server to obtain application meta information (for the log aggregation file controller’s containerlogsrequest). The storage and retrieval of application ’s current and historic information. yarn has single mapreduce job history server on master node. The storage and retrieval of application’s current and historic information in a generic fashion is addressed in. Hadoop Yarn Job History Server.